AI Coding Agents Are Meh
Updated: October 15, 2025 · 13 min
In the circles I frequent, AI (i.e. LLMs such as ChatGPT and Claude) are near universally hated. Recently, I also hated them, but, to be honest, I never really tried them before. After reading fly.io’s inflammatory and insultive article1 and seeing one person in my circle actually use and enjoy AI for coding, I tried it out and see if I really was “nuts”.
Tldr; it’s better than I thought, but it’s not “sipping rocket fuel”.
The Task
This codebase was originally forked from my professional author website, and that used the Fiber library. After looking a bit more, I settled on using Echo for new projects because of features such as data binding and other creature comforts. Even though this site’s codebase isn’t that large, changing out of the library your entire codebase is built in, while easy in this case, is tedious. In theory, this is the perfect use case for an AI agent.
The Agent
For simplicity, I went with Zed’s AI Agent feature using Claude Sonnet 3.7. Emacs is my editor of choice, but I know Zed is big on the AI shit while also not being “yet another VS Code fork”. We like originality2 here.
The Results
Oh boy, this was a mixed bag. While not perfect, most of the changes it made were a “good enough” starting point. Once I learned you need to tell it “Run go vet ./... to test your changes”3 to get it to stop writing code that won’t compile, it was even an “oh, that worked” experience. I’m not sure if I’m ashamed to say it or not, but the changes Claude made (with heavy edits) are actually running on this website.
Heavy edits?
Yeah, there was a lot of stuff it…didn’t do well. We’ll start by looking at the commit for the migration to echo. It’s a lot of boring stuff, but there are a few bugs introduced by the original Claude changes.
Looking at lines 110-123 in main.go, we can see the following diff:
1// Old (fiber)
2admin := app.Group("/admin", s.MiddlewareAdminOnly)
3admin.Get("/", s.AdminGet)
4admin.Post("/", s.AdminPost)
5admin.Post("/upload-image", s.AdminUploadImage
6
7// New (echo)
8admin := e.Group("/admin")
9admin.Use(s.MiddlewareAdminOnly)
10admin.GET("", s.AdminGet)
11admin.POST("", s.AdminPost)
12admin.POST("/upload-image", s.AdminUploadImage)
If you look closely, you’ll see that the s.AdminGet and s.AdminPost routes have a slash in the fiber version but not the echo version. In fiber, you can go to https://raine.ing/admin and get redirected to the homepage (expected behaviour). In echo, you get a 404. If you instead go to https://raine.ing/admin/ in echo, though, you’ll hit the redirect. Claude didn’t catch this behaviour difference between the two and did not remove the slash in the routes.
While not a bug, another disappointing thing I found in a follow-up commit was Claude deciding4 to create custom HTTP errors in Echo rather than use the built-in errors.
1// Bad
2return echo.NewHTTPError(http.StatusInternalServerError)
3// Good
4return echo.ErrInternalServerError
These seem like small edits so far.
We’re getting there.
I expected this endeavour to be hilariously bad, but it actually impressed me. Not enough to pay for a Cursor subscription, but enough for me to want to experiment with it some more.
After migrating from fiber to echo, I wanted to take advantage of echo’s binding feature while also using the go-playground/validator library to make sure the requests we’re receiving are valid.
This went fine as well, though most of the useful error messages I had were lost.
1// Old
2if !isValidPassword(password) {
3 return Render(c, views.Register("Password must be between 8 and 255 characters in length."))
4}
5
6// New
7if err := c.Validate(registerForm); err != nil {
8 return Render(c, views.Register("Please ensure all fields are filled correctly."))
9}
This carried over to ~6 other places where the human code had useful errors instead of that garbage you see on corporate websites when your JWT token is in a weird state, but the site pretends they don’t know what’s wrong so you open up the network tab in the dev tools only to see an internal error message in the JSON response payload that tells you your JWT token is invalid.
In a follow-up prompt, I try to fix this, but things got…weird.
We’ll start with the end state. When the validator encounters an invalid field, it will determine what validation tag caused the failure and then create a general error message for that field. Code is here and here:
1func (cv *CustomValidator) Validate(i any) error {
2 err := cv.Validator.Struct(i)
3 if err == nil {
4 return nil
5 }
6
7 validationErrors, ok := err.(validator.ValidationErrors)
8 if !ok {
9 return err
10 }
11
12 // Convert validator errors to more user-friendly messages
13 errorMessages := []string{}
14
15 for _, e := range validationErrors {
16 fieldName := e.Field()
17 switch e.Tag() {
18 case "required":
19 errorMessages = append(errorMessages, fieldName+" is required")
20 case "email":
21 errorMessages = append(errorMessages, fieldName+" must be a valid email address")
22 case "min":
23 errorMessages = append(errorMessages, fieldName+" must be at least "+e.Param()+" characters long")
24 case "max":
25 errorMessages = append(errorMessages, fieldName+" must be at most"+e.Param()+" characters long")
26 case "url":
27 errorMessages = append(errorMessages, fieldName+" must be a valid URL")
28 case "len":
29 errorMessages = append(errorMessages, fieldName+" must be exactly "+e.Param()+" characters long")
30 default:
31 errorMessages = append(errorMessages, e.Error()) // Fallback to default error
32 }
33 }
34
35 errorMessage := strings.Join(errorMessages, ". ")
36 return errors.New(errorMessage)
37}
Neat, that looks great! The best part? Claude generated this general idea, though it first wanted to assign each field’s error to a map, then convert that to a singular string using a slice as an intermediary.
1func (cv *CustomValidator) Validate(i any) error {
2 err := cv.Validator.Struct(i)
3 if err == nil {
4 return nil
5 }
6
7 validationErrors, ok := err.(validator.ValidationErrors)
8 if !ok {
9 return err
10 }
11
12 // Convert validator errors to more user-friendly messages
13 errorMap := new(map[string]string)
14
15 for _, e := range validationErrors {
16 fieldName := e.Field()
17 switch e.Tag() {
18 case "required":
19 errorMap[fieldName] = fieldName + " is required"
20 case "email":
21 errorMap[fieldName] = fieldName + " must be a valid email address"
22 case "min":
23 errorMap[fieldName] = fieldName + " must be at least "+e.Param()+" characters long"
24 case "max":
25 errorMap[fieldName] = fieldName + " must be at most"+e.Param()+" characters long"
26 case "url":
27 errorMap[fieldName] = fieldName + " must be a valid URL"
28 case "len":
29 errorMap[fieldName] = fieldName + " must be exactly "+e.Param()+" characters long"
30 default:
31 errorMap[fieldName] = e.Error() // Fallback to default error
32 }
33 }
34
35 errorMessages := []string{}
36 for _, err := range errorMap {
37 errorMessages = append(errorMessages, err)
38 }
39
40 errorMessage := strings.Join(errorMessages, ". ")
41 return errors.New(errorMessage)
42}
No idea, but whatever. Easy fix. The real weirdness came next. As we can see from the existing error handling, error messages are displayed by passing in a string when rendering a Templ component.
1msg := ""
2if err != nil {
3 // Format error to be meaningful
4 msg = err.Error()
5}
6
7return Render(c, views.Register(msg))
Instead of directly using the translated errors from the validator, Claude completely forgot it made that change and wrote a whole new error translator for each HTTP handler…
1errorMsg := "Please ensure all fields are filled correctly."
2
3if validationErrors, ok := err.(validator.ValidationErrors); ok {
4 for _, e := range validationErrors {
5 switch e.Field() {
6 case "Name":
7 if e.Tag() == "required" {
8 errorMsg = "Name is required."
9 }
10 break
11 case "Email":
12 if e.Tag() == "required" {
13 errorMsg = "Email address is required."
14 } else if e.Tag() == "email" {
15 errorMsg = "Please enter a valid email address."
16 }
17 break
18 case "Password":
19 if e.Tag() == "required" {
20 errorMsg = "Password is required."
21 } else if e.Tag() == "min" {
22 errorMsg = "Password must be at least 8 characters long."
23 } else if e.Tag() == "max" {
24 errorMsg = "Password must be at most 255 characters long."
25 }
26 break
27 }
28 }
29}
Why???
Syntax Highlighting
I remembered I wanted to add syntax highlighting to this blog, but I always found the official tutorial obtuse and annoying to reason about. Well, this was a problem contained to a singular file, so the chances of Claude doing a good job should skyrocket.
And it did a great job!
1func renderCodeWithSyntaxHighlighting(w io.Writer, code []byte, lang string) {
2 if lang == "" {
3 // If no language is specified, use the default rendering
4 writeDefaultCodeFormatting(w, code)
5 return
6 }
7
8 lexer := lexers.Get(lang)
9 if lexer == nil {
10 lexer = lexers.Fallback
11 }
12
13 style := styles.Get("gruvbox")
14 if style == nil {
15 style = styles.Fallback
16 }
17
18 formatter := chromahtml.New(
19 chromahtml.WithClasses(false),
20 chromahtml.WithLineNumbers(true),
21 )
22
23 iterator, err := lexer.Tokenise(nil, string(code))
24 if err != nil {
25 writeDefaultCodeFormatting(w, code)
26 return
27 }
28
29 var buf bytes.Buffer
30 err = formatter.Format(&buf, style, iterator)
31 if err != nil {
32 writeDefaultCodeFormatting(w, code)
33 return
34 }
35
36 //nolint
37 w.Write(buf.Bytes())
38}
39
40func writeDefaultCodeFormatting(w io.Writer, code []byte) {
41 // Omitted for brevity...
42}
43
44func Render(content string) string {
45 extensions := parser.CommonExtensions | parser.Footnotes
46 doc := parser.NewWithExtensions(extensions).Parse([]byte(content))
47 htmlParser := html.NewRenderer(html.RendererOptions{Flags: html.CommonFlags})
48 p := parser.NewWithExtensions(extensions)
49 doc := p.Parse([]byte(content))
50
51 return string(markdown.Render(doc, htmlParser))
52 htmlFlags := html.CommonFlags | html.HrefTargetBlank
53 opts := html.RendererOptions{
54 Flags: htmlFlags,
55 RenderNodeHook: func(w io.Writer, node ast.Node, entering bool) (ast.WalkStatus, bool) {
56 if codeBlock, ok := node.(*ast.CodeBlock); ok && entering {
57 renderCodeWithSyntaxHighlighting(w, codeBlock.Literal, string(codeBlock.Info))
58 return ast.SkipChildren, true
59 }
60 return ast.GoToNext, false
61 },
62 }
63
64 renderer := html.NewRenderer(opts)
65 return string(markdown.Render(doc, renderer))
66}
The only issue I encountered here was that Claude pulled in v0.10 of Chroma, while the current version is v2.18… An easy to make 3 year mistake…
Anyway, in the spirit of insanity, let’s do it again, but with live commentary!
Do It Live
Claude didn’t migrate all the form values to use Echo’s binding feature, so let’s ask it to fix that.
Use echo’s binding feature for the form values when creating and editing posts. Validate them using the go-playground/validator library.
Initially, it gives us this!
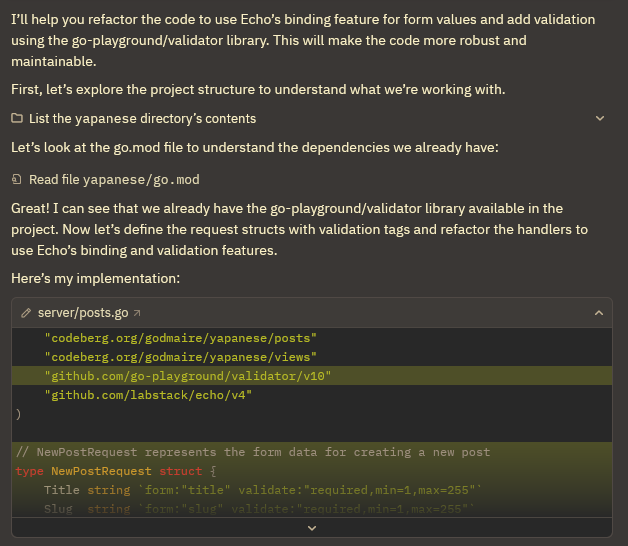
We won’t look at the diff in the screenshot, because that’s not the actual result yet. Claude continues and tries to add validation.

Neat, it found a bug in its own code. The diff for this is short, so here it is.
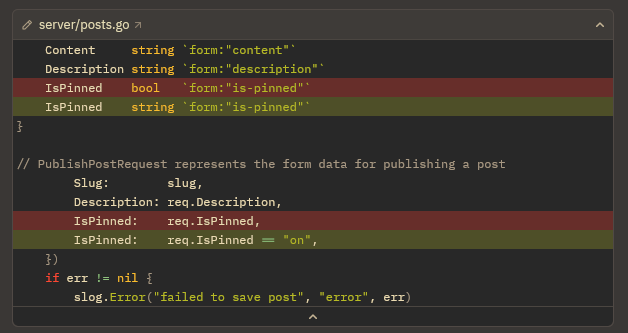
And now the summary.

Cool, but what code changes did it actually make?
Because of the length of the diff, we’ll look at two parts: the structs it generated for us to bind our data to and the binding logic for the Post Publish handler.
1// NewPostRequest represents the form data for creating a new post
2type NewPostRequest struct {
3 Title string `form:"title" validate:"required,min=1,max=255"`
4 Slug string `form:"slug" validate:"required,min=1,max=255"`
5}
6
7// UpdatePostRequest represents the form data for updating a post
8type UpdatePostRequest struct {
9 Title string `form:"title" validate:"required,min=1,max=255"`
10 Content string `form:"content"`
11 Description string `form:"description"`
12 IsPinned bool `form:"is-pinned"`
13}
14
15// PublishPostRequest represents the form data for publishing a post
16type PublishPostRequest struct {
17 Title string `form:"title" validate:"required,min=1,max=255"`
18 Description string `form:"description" validate:"required"`
19 Date string `form:"date" validate:"required,datetime=2006-01-02"`
20}
The structs are…meh. NewPostRequest has a length constraint, which is fine, UpdatePostRequest, even without requiring all the fields, is fine, but PublishPostRequest is wrong. Description is an optional field, so an empty string5 is absolutely a valid state for it to be. This is an easy fix, but it’s a bug that is very easy to miss.
And the binding logic itself?
1 slug := c.Param("slug")
2- title := c.FormValue("title")
3- description := c.FormValue("description")
4- date, err := time.Parse(
5- "2006-01-02",
6- c.FormValue("date"),
7- )
8+
9+ var req PublishPostRequest
10+ if err := c.Bind(&req); err != nil {
11+ slog.Error("failed to bind publish request", "error", err)
12+ return echo.ErrBadRequest
13+ }
14+
15+ if err := c.Validate(&req); err != nil {
16+ slog.Error("invalid publish request", "error", err)
17+
18+ row, getErr := s.Database.GetPost(c.Request().Context(), slug)
19+ if getErr != nil {
20+ slog.Error("failed to get post", "error", getErr)
21+ return echo.ErrInternalServerError
22+ }
23+
24+ return Render(c, views.Editor(row.ToMetadata(), row.Content))
25+ }
26+
27+ date, err := time.Parse("2006-01-02", req.Date)
28 if err != nil {
29- slog.Error("failed to parse date", "error", err, "date", c.FormValue("date"))
30+ slog.Error("failed to parse date", "error", err, "date", req.Date)
31 return echo.ErrInternalServerError
32 }
33
34 err = s.Database.PublishPost(c.Request().Context(), db.PublishPostParams{
35 Slug: slug,
36- Title: title,
37- Description: description,
38+ Title: req.Title,
39+ Description: req.Description,
40 CreatedAt: date,
41 UpdatedAt: date,
42 })
First, apologies for the lack of syntax highlighting; the chroma library only supports a language or a diff, unless you do some work to pre-process the diff to find the ranges.
Second, wow, that’s doing a lot more work than the original. Rather than assuming the post exists, then throwing an error if it doesn’t, Claude wants us to make a database call to ensure the row exists. What happens if we try to publish a nonexistent row? Nothing. Literally nothing. This is the smallest class of bug, and it’s not one I asked Claude to fix (single purpose PRs are better).
Funny enough, Echo also supports binding path params as well, but Claude chose to not include the path parameters in the bind. While true to the prompt, it’s something I wish it would have done.
Ultimately, I’m so unhappy with this result that I rejected all the changes. This issue could likely be solved by telling Claude “do as little work as possible” alongside a few more specific instructions, but that only tries to guard against the most annoying aspect of Agentic editing.
Overeager Intern
Is there anything wrong with this code block?
1for idx := range cookieLen {
2 sel, err := rand.Int(rand.Reader, big.NewInt(int64(len(chars))))
3 if err != nil {
4 slog.Error("we're fucked", "error", err)
5 panic(err)
6 }
7
8 cookie[idx] = chars[sel.Int64()]
9}
Well, Claude thinks it needs some tender love and care.
1for i := 0; i < cookieLen; i++ {
2 sel, err := rand.Int(rand.Reader, big.NewInt(int64(len(chars))))
3 if err != nil {
4 slog.Error("error generating random number", "error", err)
5 panic(err)
6 }
7
8 cookie[i] = chars[sel.Int64()]
Personally, I believe that if we can’t generate a random number, we’re fucked. Claude likes to be particular and not vulgar, so I understand the message change, but the rest? idx to i? Switching from the new range syntax to the old??? Fuck, Go’s LSP throws up a warning and tells you “please use the new loop syntax”, but Claude disagrees.
Whatever, I reject the changes.
Next prompt. It appears again. Reject changes.
Next prompt. Again.
Claude, I asked you to migrate from fiber to echo, use echo’s binding feature, and then improve the error messages. Why are you changing a loop that’s used when generating a cookie?
This is when I realized that LLM agents do as much as possible at once to look “impressive” and save on computing power. When Claude does more things per request, they’re able to run fewer requests. Even if each request takes 50% more energy, if they can run 50% the number of requests, then they’re saving money. To add to this, the costs are passed to the consumer (that’s you!) as request fees and limits. If you only get 500 prompt requests using Zed’s $20 per month tier, then you might be motivated to make large prompts that do multiple things at once in order to not burn through your quota.
That’s not good. At the current state (and maybe forever), LLM agents are best when making simple, isolated changes. If they do something wrong, it’s easier to spot a mistake in a bug fix diff rather than a bug fix and refactor diff. When using an LLM agent, you’re essentially becoming a code reviewer. When you review a PR, do you want to review a 50 line bug fix, or a 150 line bug fix and refactor? I know my answer, and LLM agents reward the wrong one.
What Now?
I’m not sure.
LLMs are called “plagiarism machines” in certain circles for a reason. Ethically, LLM models are created by and (“hopefully”) generate a profit for companies whose entire business model relies on IP laws while flagrantly ignoring those same IP laws to create those LLMs. Even if we solve all the other problems, we still have that to deal with. Do we admit that large corporations are allowed to pull a “rules for thee, but not for me” as long as we like the product enough? Do we give up all future LLM innovation by enforcing those IP laws? Or do we abolish IP laws entirely?
I’m not sure. We all have our theories, but no one knows what’s going to actually happen. Even if these large corporations lobby governments, those laws still need to be internally consistent. That’s difficult to do if you’re trying to strengthen and weaken IP laws at the same time. We haven’t even talked about how much money is being lost by these companies either. Prices will skyrocket, and no one knows whether the price to performance ratio will be adequate for LLMs to be worth using.
Will I continue using AI Agent editing? I don’t know. Maybe. Maybe not. What I do know is that I’m in a privileged position to competently use these tools. If you don’t know enough about coding, then you don’t know whether the code generated by the LLMs is working, let alone good. This also applies to developers using these tools in a language they are unfamiliar with as well.
The one thing I know is that these AI agents will be the minority of the lines of code I write. If I don’t write more lines of code than it writes for me, I will lose these skills I’ve spent years cultivating.
- While I’m linking it for the sake of integrity, I want to be clear that giving any attention to this is the wrong thing to do.
- And good Vim modes.
- Yes, I know
go vetis not testing, but I’ve been putting off writing a test suite for this blog for…a while. - Quick note, LLMs cannot “decide” anything. All they do is take in input and then spit it pseudo-random output. Sure, that pseudo-random output has been tuned to look like thoughts and decisions, but it’s not. LLMs are far more similar to the iOS keyboard’s autocomplete than actual intelligence.
- For the unaware, go-playground/validator considers a field missing if it’s the zero value for a type. An empty string for a variable of type
stringwould be missing, but an empty string for a variable of type*stringwould not be, because the zero value for*stringisnil.